Несколько лет назад я организовывал заметки по методу Zettelkasten в VS Code, с тех пор все поменялось, во многом из-за экспоненциального развития LLM и agentic AI. Хочу поделиться свежим стеком инструментов, которые помогают снизить когнитивную нагрузку и не терять информацию в условиях дефицита времени: PARA × Obsidian × Granola × Claude.
Статья называется «Второй мозг», а значит, мы будем строить систему, напоминающую структуру мозга человека.
graph LR
S@{ shape: text, label: "Звук" }
T@{ shape: text, label: "Текст" }
I@{ shape: text, label: "Изображения" }
S e1@--> A[**Слуховая кора**
*Захватывает и обрабатывает звук*]
T e2@--> B[**Зрительная кора**
*Захватывает и обрабатывает визуальные образы*]
I e3@--> B
A e4@--> C[**Гиппокамп**
*Маршрутизирует и индексирует информацию*]
B e5@--> C
C e6@--> mem
mem e7@--> F[**Префронтальная кора**
*Анализ, планирование, принятие решений*]
e1@{ animate: true, curve: linear }
e2@{ animate: true, curve: linear }
e3@{ animate: true, curve: linear }
e4@{ animate: true, curve: linear }
e5@{ animate: true, curve: linear }
e6@{ animate: true, curve: linear }
e7@{ animate: true, curve: linear }
subgraph mem[**Память**]
direction TB
short[**Кратковременная**] <--> long[**Долговременная**]
end
Элементы структуры мозга
PARA (Projects–Areas–Resources–Archives) — простая модель организации информации, которую сформулировал Тиаго Форте. Суть — разделить все на четыре директории: актуальные Projects, долгосрочные Areas, Resources как хранилище документов и Archives с завершенными проектами. Тиаго написал целую книгу об этой модели в 2023 году, но в 2026 — продуктивнее узнать детали у LLM.
Obsidian — бесплатный инструмент для организации заметок в markdown-формате. И для работы с текстом он на порядок удобнее VS Code: редактирование документов в режиме live-preview, большая база плагинов, есть mobile-версия. VS Code оставим для написания кода и технической документации, а Obsidian для заметок и ведения базы знаний. Он просто удобнее, попробуйте.
Признаюсь, я отдельно кайфую от того, что для максимальной продуктивности сейчас необходимо писать в Markdown, иметь базовые навыки работы с терминалом, разобраться, наконец, что такое GitHub, MCP, RAG, A2A и куча других новых технологий вокруг AI. И вижу, как кайфуют от этого люди, близкие к технологиям. Инструменты, которые раньше использовались исключительно разработчиками, становятся массовыми. На GitHub появляются профили дизайнеров, маркетологов и специалистов из совершенно нетехнических областей, которые пишут skills для агентов и запускают собственные pet-проекты.
В 2025 году на GitHub создано 121 миллион новых репозиториев — рекорд за всю историю платформы.
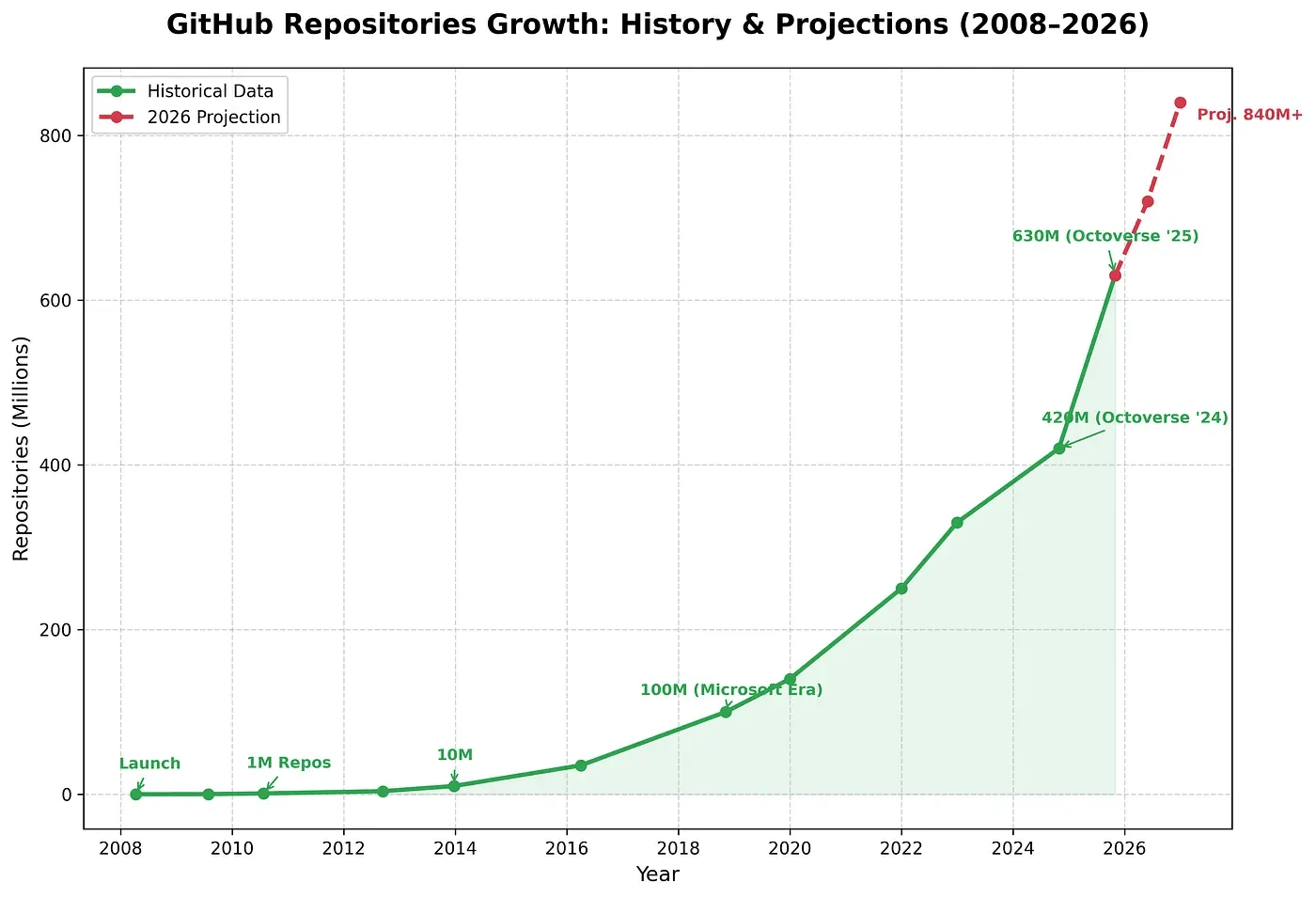
Количество репозиториев на GitHub
Отдельно подчеркну: markdown — это формат, который однозначно понимает любая LLM, в отличие от .docx, .pdf и других форматов документов. И это не только заголовки и списки — вот полная спецификация. Markdown переживет любой инструмент. Evernote умирает, Notion однажды закроется, Google Docs привязан к аккаунту, md-файл откроется через 20 лет в любом текстовом редакторе — это plain text.
Granola — сервис для записи, транскрибации и создания заметок по итогам встреч. Работает и на смартфоне, и на компьютере, подходит для онлайн и офлайн-встреч. Отлично справляется с русским языком. Забавно, но на выходе Granola создает md-файлы (естественно), и один Obsidian-энтузиаст написал плагин Granola-to-Obsidian, который синхронизирует заметки прямо в рабочее пространство Obsidian.
Здесь возникает важный вопрос про информационную безопасность, особенно если использовать сервис в рабочих задачах. Транскрибация в Granola происходит локально на устройстве — аудио никуда не уходит. Однако для генерации заметок Granola по умолчанию отправляет транскрипт в ChatGPT. Поэтому я использую для этого шага внутреннюю корпоративную LLM.
Claude Code — agentic AI с доступом к файловой системе, в нашем случае — к папке Obsidian vault. Он может читать, редактировать, создавать и анализировать любые файлы в этом пространстве. По названию может показаться, что он предназначен только для написания кода, но это не так — он отлично справляется с анализом и работой над любыми текстовыми документами. Интересная особенность, что взаимодействие с Claude Code происходит в терминале. Но, поверьте, он настолько удобен, что не вызывает каких-либо сложностей.
Obsidian и Claude Code CLI
У Claude есть и другие инструменты: веб, десктоп, мобильное приложение, расширения для Chrome, Excel и PowerPoint. Они закрывают свои задачи, но не имеют прямого доступа к файлам в Obsidian vault — а значит, в контексте нашего умного стека ключевой инструмент именно Claude Code.
Какие задачи доверять Claude, каждый решает сам. Мое правило простое: я делегирую только то, что могу проверить. Либо я понимаю, как это реализовать, и Claude экономит мне время. Либо я точно знаю, что хочу получить на выходе, и могу оценить результат.
К слову, эту статью я пишу совместно с Claude — он подсказывает, где текст звучит сложно или двояко, исправляет опечатки, обрабатывает изображения и правит CSS-стили, помогает с диаграммами. Claude помог мне за один вечер перенести все статьи из старого блога на WordPress в новый на Hugo — я давно планировал это сделать, но до того, как LLM научились писать код, задачка выглядела тяжеловатой.
Обращаю внимание, что файлы, к которым обращается Claude Code, передаются на внешние серверы. Но для конфиденциальных данных есть решения: корпоративная версия, где данные остаются внутри вашей инфраструктуры и защищены юридически, или даже локальный запуск с open-source моделями через Ollama.
Вернемся к аналогии рассматриваемого стека со структурой мозга человека:
graph LR
S@{ shape: text, label: "*Звук*" }
T@{ shape: text, label: "*Текст*" }
I@{ shape: text, label: "*Изображения*" }
S e1@--> A[**Слуховая кора**
Granola]
T e2@--> B[**Зрительная кора**
/Resources]
I e3@--> B
A e4@--> C[**Гиппокамп**
PARA]
B e5@--> C
C e6@--> mem
mem e7@--> F[**Префронтальная кора**
Claude Code]
e1@{ animate: true, curve: linear }
e2@{ animate: true, curve: linear }
e3@{ animate: true, curve: linear }
e4@{ animate: true, curve: linear }
e5@{ animate: true, curve: linear }
e6@{ animate: true, curve: linear }
e7@{ animate: true, curve: linear }
subgraph mem[**Память**]
direction TB
Obsidian@{ shape: text, label: "Obsidian vault" } ~~~
short[**Кратковременная**
/Inbox
/Projects] <--> long[**Долговременная**
/Areas
/Archive]
end
Аналогия стека со структурой мозга
Каждый инструмент в стеке выполняет свою роль: Granola захватывает входящий поток (слуховая кора), PARA маршрутизирует информацию (гиппокамп), Obsidian хранит знания (память), а Claude Code анализирует и помогает принимать решения (префронтальная кора).
К этому стеку я пришел после долгих экспериментов и борьбы с хаосом разрозненного хранения документов между локальным диском, облаками, избранным в Telegram и различными todo-приложениями. Пока что — полет устойчивый.