В этой заметке хочу разобрать как вручную посчитать 3 вида метрики Retention с помощью Python и Pandas и нарисовать кривую Retention с помощью Matplotlib. Чаще всего для анализа данных и метрик любой продакт будет использовать аналитическую систему, но предположим, что наш продакт попал на необитаемый остров и под рукой у него оказались только интерпретатор Python-скриптов и несколько дополнительных библиотек; этим и воспользуемся.
Для начала, в двух словах напомню про метрику и её виды; как они считаются.
Classic Retention Rate (удержание) — это метрика, которая показывает процент пользователей, вернувшихся в продукт в конкретный день N (неделю N, месяц N, квартал N, etc.) с момента первого посещения. Например, если в день 0 пришло 100 новых пользователей, а в 1-й день вернулось 15, то Retention 1-го дня — 15 / 100 = 15%.
Rolling Retention Rate (повторяющееся удержание) — показывает процент пользователей, вернувшихся в продукт в день N или позже с момента первого посещения. Например, два пользователя впервые посетили продукт в один и тот же день (день 0). Один из них вернулся в 1-й день, второй — на 5-й день. Они оба будут считаться вернувшимися в 1-й день.
Full Retention Rate (полное удержание) — показывает процент пользователей, заходивших в приложение каждый день до дня N с момента первого посещения. Например, Full Retention Rate 3-го дня — это процент пользователей, которые заходили в продукт в 1-й, 2-й и 3-й дни с момента первого посещения.
Retention можно считать в окнах разного размера: по дням; по неделям; по месяцам; по кварталам. Далее в заметке будем работать с дневным Retention.
На GoPractice есть замечательные подробные статьи по метрикам Retention и даже референсным значениям: [раз], [два] и [три]. Я далее сосредоточусь на том, как эти метрики считать вручную.
Данные для исследования
Для расчетов будем использовать синтетический dataset состоящий из двух полей (столбцов): «user_id» — уникальный ID пользователя; «date» — дата посещения продукта. Исходный dataset можно найти по ссылке, вот так выглядят его первые 10 строк:
| user_id | date |
|---|---|
| e554f976-36eb-4d07-be19-144ff7f1b416 | 2020-01-05 |
| 4e849e4a-6bc9-45ac-8398-5cea217430de | 2020-01-06 |
| 86a4be3a-e13c-4e7d-a017-34799c866425 | 2020-01-06 |
| 6c3f44bb-441d-4640-899a-f96e1918064b | 2020-01-02 |
| 0f4bd366-8433-4ea9-b7e3-5e507fcfaa02 | 2020-01-23 |
| 0a0bb591-4e64-4751-9c58-898d0ebf9d95 | 2020-01-18 |
| d75a6f2a-145e-4183-bb8a-e2d95c93c154 | 2020-01-29 |
| 67889f56-a58e-4122-b015-42dccc5a2ec2 | 2020-01-01 |
| 5da0336e-2cce-48c8-94e9-c0968433d930 | 2020-01-02 |
| b8df8afb-23ed-4a0f-bb1d-4b5f5a2a94fd | 2020-01-25 |
Подключаем необходимые библиотеки и загружаем его в Pandas Dataframe.
1import pandas as pd
2import matplotlib.pyplot as plt
3import matplotlib.ticker as mtick
4
5# Путь к файлу с данными
6dataset_path = 'https://data/retention-dataset.csv'
7
8# Чтение данных и парсинг даты
9df = pd.read_csv(dataset_path, parse_dates=['date'])
Считаем Classic Retention
Теперь напишем функцию calculate_classic_retention, которая по переданному DataFrame будет рассчитывать Classic Retention для нужных нам дней. DataFrame и список нужных дней будем передавать на вход функции.
Для вычислений понадобится создать две дополнительные колонки в таблице (DataFrame): start_date — дата первого посещения продукта пользователем; day — кол-во дней от даты первого посещения до даты текущего посещения.
Тогда для вычисления Retention N-дня нам понадобится просто посчитать кол-во строк в колонке day (с уникальными user_id) и разделить его на кол-во всех пользователей когорты.
1def calculate_classic_retention(df: pd.DataFrame, days: list) -> list:
2
3 # Рассчитываем начальные даты для каждого пользователя и объединяем их с исходным DataFrame
4 start_date = df.groupby('user_id')['date'].min().rename('start_date')
5 df = pd.merge(df, start_date, left_on='user_id', right_index=True)
6
7 # Рассчитываем количество дней от начальной даты для каждой строки
8 df['day'] = (df['date'] - df['start_date']).dt.days
9
10 # Создаем список для хранения classic retention на каждый день
11 classic_retention = []
12
13 # Рассчитываем classic retention для каждого дня
14 for day in days:
15 # Выбираем пользователей, вернувшихся в день `day`
16 users_with_classic_day = df[(df['day'] == day)]['user_id'].unique()
17
18 # Рассчитываем classic retention для дня `day`
19 classic_retention.append(len(users_with_classic_day) / len(df['user_id'].unique()))
20
21 return classic_retention
Для визуализации кривой Retention я написал функцию plt_show, на вход которой нужно передать days — список номеров дней; retention — список вычисленных значений Retention для дней days; xs — список номеров дней, которые нужно подсветить на графике.
1def plt_show(days: list, retention: list, xs: list, title: str):
2 plt.figure(figsize=(12, 4))
3 plt.plot(days, retention)
4 plt.title(title)
5 plt.gca().yaxis.set_major_formatter(mtick.PercentFormatter(xmax=1.0))
6 plt.gca().set(xlabel='Days', ylabel='% Retaining Users')
7 plt.ylim(0, 1.05)
8 for x in xs:
9 plt.vlines(x=days[x], ymin=0, ymax=retention[x], linestyles='dotted')
10 plt.text(x=days[x], y=retention[x] + 0.05, s='{:.0%} (day {})'.format(retention[x], x))
11 plt.show()
Посчитаем Classic Retention и построим его кривую, отметим значения для 1-го, 7-го, 28-го и 56-го дней. И увидим, что на нашем синтетическом датасете синтетически-замечательные значения метрики — значительно превосходящие правило «40 — 20 — 10».
1days = list(range(0, 63))
2
3classic_retention = calculate_classic_retention(df, days)
4
5plt_show(days, classic_retention, xs=[1, 7, 28, 56], title='Daily Classic Retention')
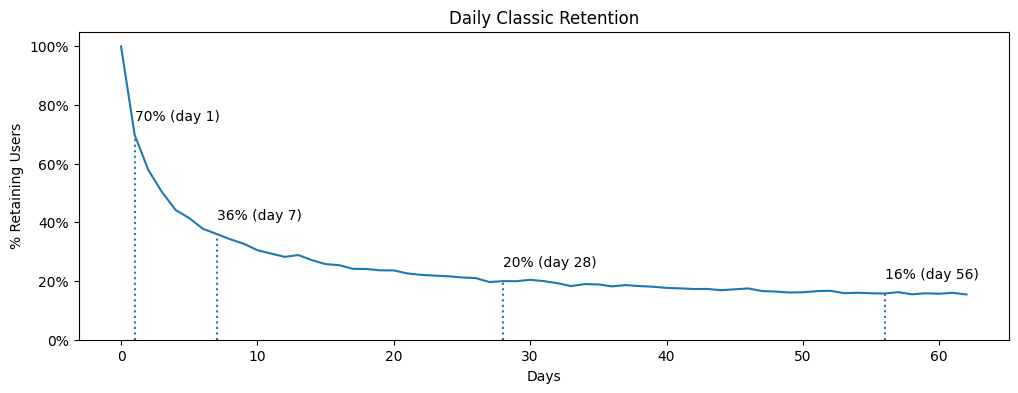
Видим, что на следующий день после первого захода в продукт — вернулось 70% пользователей, на 7 день — 36%, на 28 день — 20%. Примерно через 30 дней кривая выходит на плато, т. е. для продукта найден Product/Market Fit.
Считаем Rolling Retention
Напишем функцию calculate_rolling_retention, которая по своей логике будет практически полностью совпадать с предыдущей функцией. За исключением одного условия — теперь выберем записи, в которых порядковый номер дня более или равен дню, за который мы считаем значение метрики.
Вот это условие:
1df[df['day'] >= day]['user_id'].unique()
А вот весь код функции:
1def calculate_rolling_retention(df: pd.DataFrame, days: list) -> list:
2
3 # Рассчитываем начальные даты для каждого пользователя и объединяем их с исходным DataFrame
4 start_date = df.groupby('user_id')['date'].min().rename("start_date")
5 df = pd.merge(df, start_date, left_on='user_id', right_index=True)
6
7 # Рассчитываем количество дней от начальной даты для каждой строки
8 df['day'] = (df['date'] - df['start_date']).dt.days
9
10 # Создаем список для хранения rolling retention на каждый день
11 rolling_retention = []
12
13 # Рассчитываем rolling retention для каждого дня
14 for day in days:
15 # Выбираем пользователей, вернувшихся в день `day` или позже
16 users_with_rolling_day = df[df['day'] >= day]['user_id'].unique()
17
18 # Рассчитываем rolling retention для данного дня
19 rolling_retention.append(len(users_with_rolling_day) / len(df['user_id'].unique()))
20
21 return rolling_retention
И результат вычислений:
1days = list(range(0, 63))
2
3rolling_retention = calculate_rolling_retention(df, days)
4
5plt_show(days, rolling_retention, xs=[1, 7, 28, 56], title='Daily Rolling Retention')
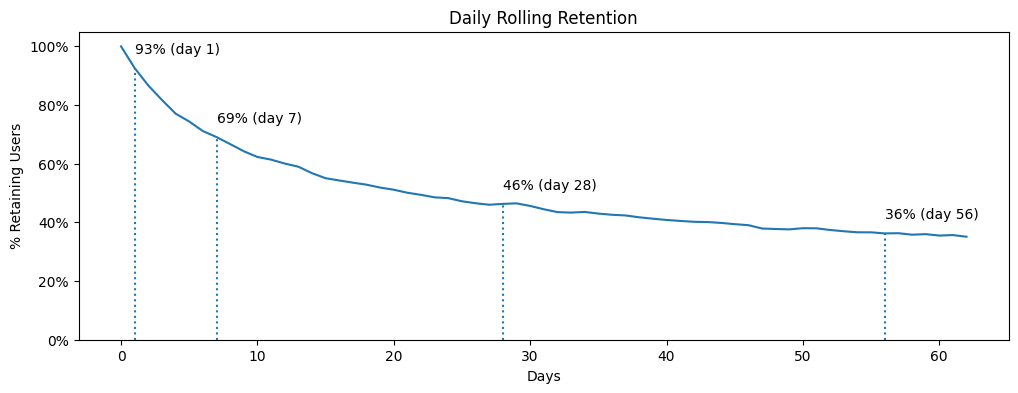
Видим, что со следующего дня после первого захода в продукт — вернулось 93% пользователей, с 7 дня — 69%, с 28 день — 46%.
Считаем Full Retention
И наконец напишем функцию для расчета Full Retention.
1def calculate_full_retention(df: pd.DataFrame, days: list) -> list:
2
3 # Рассчитываем начальные даты для каждого пользователя и объединяем их с исходным DataFrame
4 start_date = df.groupby('user_id')['date'].min().rename("start_date")
5 df = pd.merge(df, start_date, left_on='user_id', right_index=True)
6
7 # Рассчитываем количество дней от начальной даты для каждой строки
8 df['day'] = (df['date'] - df['start_date']).dt.days
9
10 # Создаем список для хранения full retention на каждый день
11 full_retention = []
12
13 for day in days:
14 # Создаем множество дней, которые мы ожидаем увидеть в полном удержании
15 expected_days = set(range(1, day + 1))
16
17 # Получаем уникальные дни активности для каждого пользователя
18 unique_days = df.groupby('user_id')['day'].unique()
19
20 # Определяем пользователей с полным удержанием до retention_day
21 full_retention_users = unique_days[unique_days.apply(lambda x: set(x) > expected_days)].index
22
23 # Рассчитываем rolling retention для данного дня
24 full_retention.append(len(full_retention_users) / len(df['user_id'].unique()))
25
26 return full_retention
1days = list(range(0, 10))
2
3full_retention = calculate_full_retention(df, days)
4
5plt_show(days, full_retention, xs=[1, 3, 6], title='Daily Full Retention')
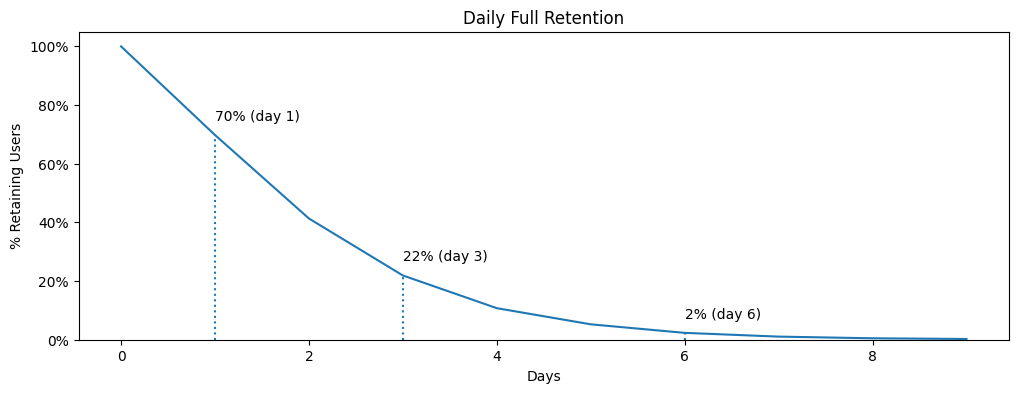
Видим, что 70% пользователей вернулись в продукт на следующий день после первого знакомства с ним. И поскольку это значение метрики совпадает со значением Classic Retention, вероятно в вычислениях я не ошибся:). 22% пользователей заходили в продукт ежедневно на протяжении 3 дней; и только 2% пользователей заходили в продукт ежедневно на протяжении 6 дней.
Выводы
- Исходные коды в [Google Colab] и на [GitHub], во-первых.
- Не существует универсальных параметров для расчета Retention для любого продукта. От специфики продукта или текущих целей продукта зависит подходящий вид метрики, окно, референсные значения.
- Тем не менее, Classic Retention более популярный показатель, чем Rolling или Full Retention.
- Посчитать метрики вручную достаточно просто, но нужна небольшая практика в инструментах продуктовой аналитики.