A few years ago I was organizing notes using the Zettelkasten method in VS Code. Since then, everything has changed — largely due to the exponential growth of LLMs and agentic AI. I want to share a fresh tool stack that helps reduce cognitive load and keep information from slipping through the cracks when time is scarce: PARA × Obsidian × Granola × Claude.
The article is called “Second Brain,” which means we’re building a system that mirrors the structure of the human brain.
graph LR
S@{ shape: text, label: "Sound" }
T@{ shape: text, label: "Text" }
I@{ shape: text, label: "Images" }
S e1@--> A[**Auditory Cortex**
*Captures and processes sound*]
T e2@--> B[**Visual Cortex**
*Captures and processes visual input*]
I e3@--> B
A e4@--> C[**Hippocampus**
*Routes and indexes information*]
B e5@--> C
C e6@--> mem
mem e7@--> F[**Prefrontal Cortex**
*Analysis, planning, decision-making*]
e1@{ animate: true, curve: linear }
e2@{ animate: true, curve: linear }
e3@{ animate: true, curve: linear }
e4@{ animate: true, curve: linear }
e5@{ animate: true, curve: linear }
e6@{ animate: true, curve: linear }
e7@{ animate: true, curve: linear }
subgraph mem[**Memory**]
direction TB
short[**Short-term**] <--> long[**Long-term**]
end
Elements of the brain's structure
PARA (Projects–Areas–Resources–Archives) is a simple information organization model developed by Tiago Forte. The idea is to split everything into four directories: active Projects, long-term Areas, Resources as a document store, and Archives for completed projects. Tiago wrote an entire book about the model back in 2023, but in 2026 it’s more efficient to just ask an LLM for the details.
Obsidian is a free tool for organizing notes in Markdown format. For working with text, it’s a step above VS Code: live-preview document editing, a rich plugin ecosystem, and a mobile app. I’ll keep VS Code for writing code and technical documentation, and use Obsidian for notes and knowledge management. It’s simply more convenient — try it.
I’ll admit, I get a particular kick out of the fact that maximum productivity today requires writing in Markdown, having basic terminal skills, finally understanding what GitHub, MCP, RAG, A2A, and a bunch of other new AI-adjacent technologies actually are. And I can see how much people close to technology are enjoying this shift. Tools that were once exclusively for developers are going mainstream. GitHub is seeing profiles from designers, marketers, and people from entirely non-technical fields — writing agent skills and launching their own pet projects.
In 2025, 121 million new repositories were created on GitHub — a record in the platform’s history.
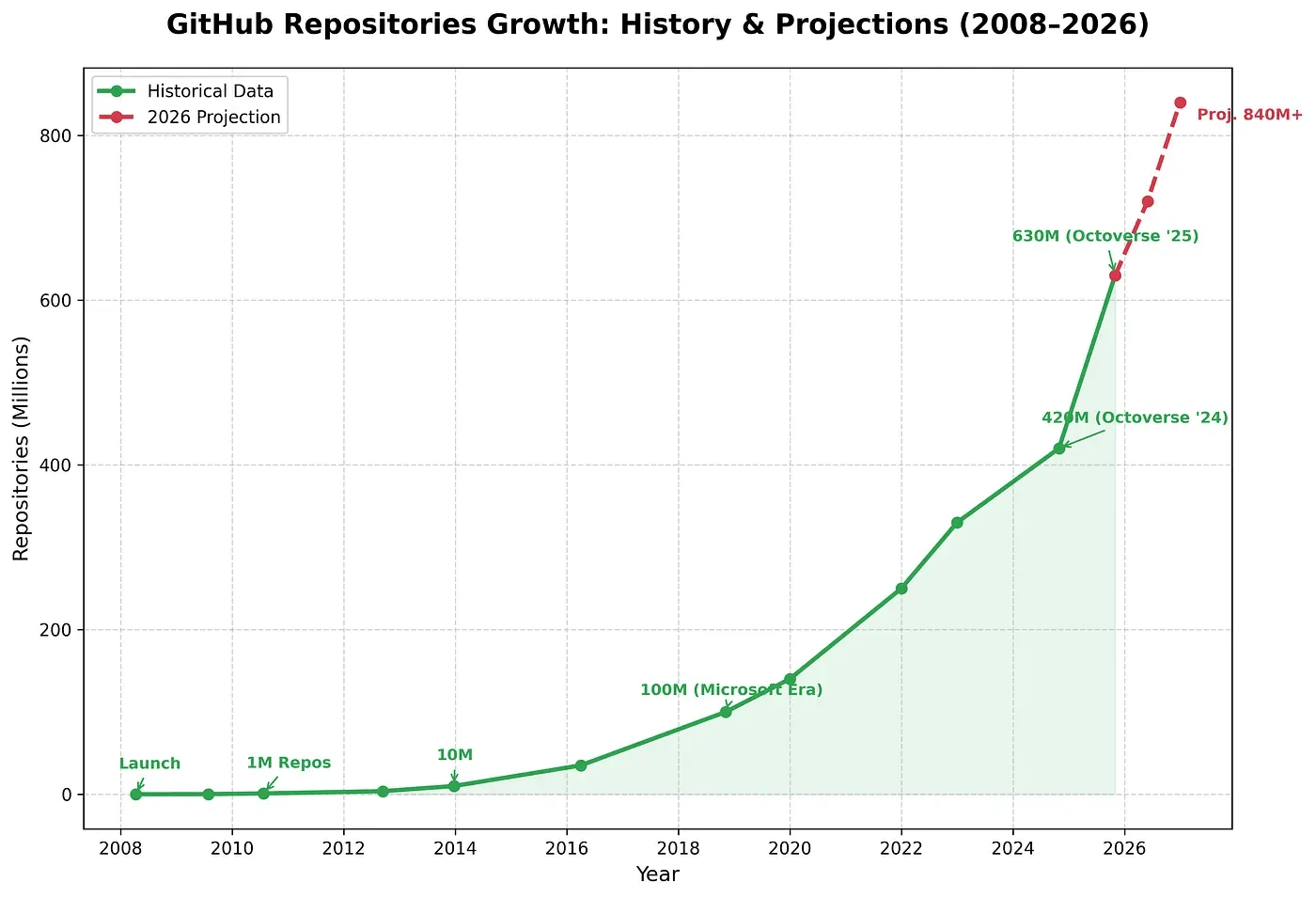
Number of repositories on GitHub
One more thing worth emphasizing: Markdown is a format that any LLM understands unambiguously, unlike .docx, .pdf, and other document formats. And it’s not just headers and lists — here’s the full spec. Markdown will outlive any tool. Evernote is dying, Notion will shut down someday, Google Docs is tied to your account — but an .md file will open in any text editor 20 years from now. It’s plain text.
Granola is a service for recording, transcribing, and generating notes from meetings. It works on both smartphone and computer, supports online and in-person meetings, and handles the English language excellently. Interestingly, Granola outputs .md files (naturally), and one Obsidian enthusiast built a Granola-to-Obsidian plugin that syncs notes directly into your Obsidian workspace.
This raises an important question around information security, especially when using the service for work. Transcription in Granola happens locally on your device — audio never leaves it. However, to generate meeting notes, Granola by default sends the transcript to ChatGPT. For that step, I use an internal corporate LLM instead.
Claude Code is an agentic AI with access to the file system — in our case, the Obsidian vault folder. It can read, edit, create, and analyze any files in that workspace. The name might suggest it’s only for writing code, but that’s not the case — it handles analysis and work on any text documents just as well. One interesting quirk: you interact with Claude Code through the terminal. But trust me, it’s intuitive enough that it doesn’t cause any friction.
Obsidian and Claude Code CLI
Claude offers other interfaces too: web, desktop, mobile app, and extensions for Chrome, Excel, and PowerPoint. They each serve their purpose, but none have direct access to files in the Obsidian vault — which is why Claude Code is the key tool in this smart stack.
What tasks you delegate to Claude is entirely up to you. My rule is simple: I only hand off things I can verify. Either I understand how to do it myself and Claude saves me time, or I know exactly what output I want and can evaluate the result.
By the way, I’m writing this article together with Claude — he flags where the text sounds awkward or ambiguous, fixes typos, processes images, tweaks CSS styles, and helps with diagrams. Claude helped me migrate all my posts from an old WordPress blog to a new Hugo site in a single evening — something I’d been putting off for a long time, mostly because before LLMs could write code, the task felt daunting.
Worth noting: the files Claude Code accesses are sent to external servers. But for sensitive data there are solutions: an enterprise version where data stays within your infrastructure and is legally protected, or even running it locally with open-source models via Ollama.
Let’s come back to the analogy between this stack and the structure of the human brain:
graph LR
S@{ shape: text, label: "*Sound*" }
T@{ shape: text, label: "*Text*" }
I@{ shape: text, label: "*Images*" }
S e1@--> A[**Auditory Cortex**
Granola]
T e2@--> B[**Visual Cortex**
/Resources]
I e3@--> B
A e4@--> C[**Hippocampus**
PARA]
B e5@--> C
C e6@--> mem
mem e7@--> F[**Prefrontal Cortex**
Claude Code]
e1@{ animate: true, curve: linear }
e2@{ animate: true, curve: linear }
e3@{ animate: true, curve: linear }
e4@{ animate: true, curve: linear }
e5@{ animate: true, curve: linear }
e6@{ animate: true, curve: linear }
e7@{ animate: true, curve: linear }
subgraph mem[**Memory**]
direction TB
Obsidian@{ shape: text, label: "Obsidian vault" } ~~~
short[**Short-term**
/Inbox
/Projects] <--> long[**Long-term**
/Areas
/Archive]
end
The stack mapped to the brain's structure
Each tool in the stack plays a distinct role: Granola captures the incoming stream (auditory cortex), PARA routes information (hippocampus), Obsidian stores knowledge (memory), and Claude Code analyzes and helps make decisions (prefrontal cortex).
I arrived at this stack after a long series of experiments and an ongoing battle with the chaos of scattered storage — documents spread across a local drive, cloud services, Telegram saved messages, and various to-do apps. So far, the flight is smooth.